How to Build Accurate Data Asset Lineage for Data Warehouse Governance
This article explains the challenges of data asset lineage in large data warehouses, presents a comprehensive approach using business‑level instrumentation, SQL interceptor plugins, and ETL script parsing to generate fine‑grained lineage graphs, and demonstrates measurable improvements in coverage and zombie‑table cleanup.
1. Background
As the automotive‑home OEM business expands, the volume of data assets and the complexity of the data warehouse increase, leading to non‑standard data models, difficult traceability, and analysis problems caused by insufficient lineage analysis. Strengthening lineage relationships is essential for effective data‑warehouse modeling, governance, and maximizing data value.
2. Problems Encountered
Inconsistent naming of data assets due to lack of enforced naming rules.
Missing dependencies in ETL task scheduling, resulting in incomplete or inaccurate lineage.
Multiple ETL script types (shell, Python, PySpark, HQL) increase parsing difficulty.
HQL files lack unified coding standards, with multiple INSERT statements and missing database names.
Unclear data asset usage at the application layer, making it hard to link assets to business scenarios.
3. Analysis Approach
3.1 Business Instrumentation
Business instrumentation embeds AOP‑based code to capture table usage and call counts, solving the unclear application‑layer asset usage problem.
a. Overall Flow
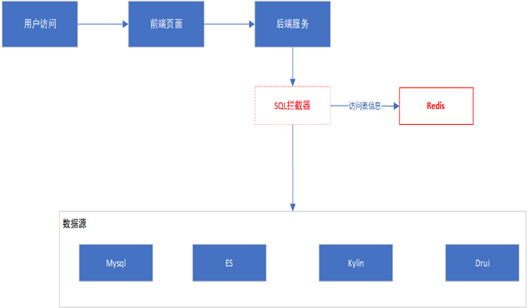
The backend service injects a MyBatis interceptor via AOP, extracting the interceptor into a separate module to reduce coupling. The interceptor centralizes SQL handling, allowing easy addition or removal of plugins without affecting business modules.
b. Usage
<dependency>
<groupId>com.autohome.index</groupId>
<artifactId>common-sqlplugin</artifactId>
<version>1.1-SNAPSHOT</version>
</dependency>c. SQL Interceptor Implementation
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class})
public class SqlPluginInterceptor implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
MappedStatement mappedStatement = (MappedStatement) invocation.getArgs()[0];
Object parameter = null;
if (invocation.getArgs().length > 1) {
parameter = invocation.getArgs()[1];
}
BoundSql boundSql = mappedStatement.getBoundSql(parameter);
long startTime = System.currentTimeMillis();
try {
return invocation.proceed();
} finally {
try {
// Store SQL and table info into Redis
saveSqlToRedis(retSQL, sqlCost, mappedStatement.getId());
} catch (Exception e) {
System.out.println("sql interceptor error!");
e.printStackTrace();
}
}
}
}3.2 ETL Task Parsing
The ETL parsing pipeline handles both regular HQL scripts and unconventional scripts (shell, Python, PySpark). Regular scripts are parsed into lineage and stored in MySQL; failures are recorded as unconventional tasks, triggering alert emails and manual handling (less than 5% of total).
a. Task Parsing Flow
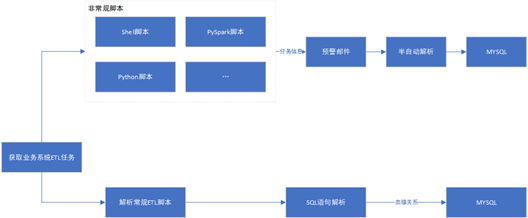
Regular ETL scripts are parsed via an SQL parser to extract lineage and write to MySQL. Unconventional scripts are aggregated, emailed for review, and processed manually.
try:
file_content = hql_parse_util.parse_hql(hqlfile)
table_dict = hql_parse_util.parse_output(file_content.lower())
for out_put_table in table_dict:
input_tables = table_dict[out_put_table]
if out_put_table == 'tbnames':
out_put_table = '.'
for input_table in input_tables:
if input_table.startswith('--'):
continue
sql_val.append([hqlfile, out_put_table.split('.',1)[0], out_put_table.split('.',1)[1],
input_table.split('.',1)[0], input_table.split('.',1)[1], uid, name, 'hive', job_status, date_time])
cnt = cursor.executemany(insert_sql, sql_val)
print('Inserted regular tasks: ' + str(cnt) + ' rows')
conn.commit()
finally:
cursor.close()3.3 SQL Statement Analysis
SQL parsing distinguishes source tables (including WITH blocks) and target tables (INSERT statements). The parser extracts table names, resolves database names via USE statements, and maps WITH aliases to actual tables.
With‑block Parsing
def sql_parse(sql):
sql = sql.lower()
with_tb_dict = {}
sql = re.sub('with[-_a-z]', '', sql)
if 'with' in sql:
with_all_arr = sql.split('with')[1:]
for with_content in with_all_arr:
# Extract alias and inner SELECT tables
...
print(with_tb_dict)Table Name Extraction
def sql_parse_get_tablenames(sql_query):
table_names = re.findall(r'from\s+(\S+)', sql_query, re.IGNORECASE)
table_names += re.findall(r'join\s+(\S+)', sql_query, re.IGNORECASE)
tb_names = []
for name in table_names:
if '(' not in name:
tb_names.append(name.replace(')', '').replace('`', '').replace(';', ''))
return list(set(tb_names))USE‑statement Handling
if 'use ' in sql:
use_arrs = sql.split('use ')[1:]
for arr in use_arrs:
db_name = arr.split(';')[0]
if 'insert' in arr:
insert_arr = arr.split('insert ')[1:]
for tb in insert_arr:
if 'into' in tb:
insert_tb = tb[tb.index('into ') + len('into '):tb.index('
')].strip()
else:
insert_tb = tb[tb.index('table ') + len('table '):tb.index('
')].strip()
hive_target_tb = insert_tb.split(' ')[0]
if '.' not in hive_target_tb:
hive_target_tb = db_name + '.' + hive_target_tb
# further mapping logic ...4. Analysis and Governance Results
4.1 Lineage Coverage Metric
A quantitative metric, "lineage coverage", measures the proportion of assets with at least one lineage link. Calculation steps:
Define the set of assets to monitor.
Identify lineage relationships via SQL parsing.
Compute coverage = (number of covered assets) / (total assets).
Compare coverage with other indicators to spot uncovered assets and missing links.
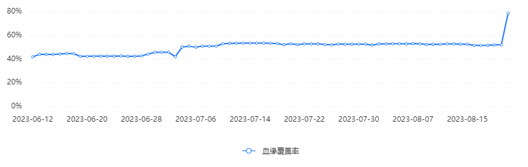
4.2 Zombie‑Table Governance
By counting table usage frequency from business instrumentation and comparing with the full catalog, tables unused for long periods ("zombie tables") are identified. The cleanup process backs up data, drops the table, waits a month for any issues, then permanently deletes from backup. Approximately ten zombie tables are removed weekly.

5. Summary
Data asset lineage analysis helps organizations understand data flow, assess risks, and improve governance. The process includes defining goals, collecting assets, parsing relationships, analyzing lineage, assessing risk, generating reports, and providing optimization recommendations.
6. Future Plans
Upcoming work will focus on data‑quality assurance, multi‑source integration, and building visual lineage graphs. Specific actions include establishing stricter data‑quality policies, integrating internal and external data sources, continuously optimizing the lineage model, visualizing relationships, and defining standards for reproducible lineage analysis.
Signed-in readers can open the original source through BestHub's protected redirect.
This article has been distilled and summarized from source material, then republished for learning and reference. If you believe it infringes your rights, please contactand we will review it promptly.
How this landed with the community
Was this worth your time?
0 Comments
Thoughtful readers leave field notes, pushback, and hard-won operational detail here.